Posted On: June 19 2025 - Written On: March 16 2025
A Collection of Recent Thoughts on AI's Past, Present and Future
This post originally appeared in the newsletter of Stanford University's Quantum Mechanical Engineering Lab
Background
OpenAI launched its ChatGPT application in November 2022, and it has been a wild ride for AI ever since. Despite having been a relatively niche field of computer science, AI is now commonly featured in the headlines of major newspapers. Specialists across various fields, from philosophers to politicians, are expressing their views and becoming involved with the technology. Their claims have varied widely, with Noam Chomsky describing ChatGPT as “high-tech plagiarism” [1], while politicians aim to make their countries the global hub for AI technology. Investors are also hoping to ride the wave of the AI revolution.
All of this is happening amidst reports, such as those from Goldman Sachs, that question whether AI's real benefits justify its costs [2]. Additionally, the launch of the highly performant DeepSeek models from a relatively small Chinese company has challenged incumbents and demonstrated that barriers to entry may not be as high as originally thought, complicating the picture about payoff even further.
The breadth of views is, in a way, understandable. The public, politicians, and other non-specialists are trying to grasp an esoteric technology that is evolving rapidly. While people educated in the sciences, especially in physics, can feel at home with AI technology, the situation is not so simple for non-scientists.
For example, both the so-called Bahdanau Attention [3], which gave rise to the first Transformers [4], and the vanilla Machine Learning (ML) algorithm for classification utilize the partition function, a concept that will be instantly recognizable to physicists and engineers. Indeed, in Large Language Models (LLM), the so-called hallucinations can be controlled by a parameter called temperature.
Conversely, the landscape is more complex for those without a scientific background. Modern AI relies on Machine Learning (ML), a technology whose terminology can often be misleading. We talk about “training” an algorithm instead of fitting parameters. The algorithm itself consists of “neurons,” and it also “hallucinates.” Even experts are sometimes confused about where the limits of the technology lie. In fact, there is so much written about AI, often by people lacking expertise in the field, that it is not uncommon to see terms being used incorrectly.
Recent AI Developments
To understand a little more about the technology behind AI, let's review some recent developments. Focusing on generative AI and text generators, we see that there have been many attempts to have machines generate text. Text generators from previous decades (e.g., those using Markov chains) were able to produce seemingly meaningful text, which, upon closer examination, was actually nonsensical. Here is an example [5]:

Even just a few years ago, Neural Network models struggled to accurately capture the grammar and semantic meaning of words. The invention of Bahdanau Attention [3] (which allows the algorithm to place more weight on certain key words) and the Transformer architecture [4] gave rise to modern LLMs, which simply predict the next word (or token, to be more precise) based on a probability distribution conditioned on the words (tokens) already present in the text.
As a concept, this is nothing new; by repeating the process described above, it is easy to see how one can create entire passages. What is truly impressive, however, is how powerful this relatively simple game of “predicting the next word” can be, when played at a large enough scale.
Indeed, the latest LLMs, which are the AI engines of applications like ChatGPT, have on the order of a trillion parameters! This is in stark contrast to the familiar two-parameter model used to teach the Least Squares method to high school students around the world. Empowered by the Universal Approximation Theorem (which essentially states that a sufficiently large Neural Network can approximate any continuous function) and the ever-growing computational power, researchers in the ML field have, for years, been making their Neural Networks larger to achieve better performance.
Typically, size can increase up to a point beyond which we do not see significant improvements. Of course, Neural Network size is also limited by the available computing power, and significant advancements in computing, such as quantum computing, have the potential to dramatically change the landscape of AI models. The availability of high-quality data is important as well. In fact, given that everyone uses the same family of algorithms (described in detail in freely-available scientific publications) and that access to significant computing power is relatively affordable through the cloud, high-quality data often end up being the differentiating factor between good and great models.
The idea of generating text based on a probability distribution brings to mind the short story "The Library of Babel," by Jorge Luis Borges. In the story, the books in the library contain all the possible combinations of the letters in the alphabet. As a result, there exists a book that describes a person’s death exactly, as well as a book that defines Quantum Mechanical Theory and even other potentially groundbreaking theories from the future that have yet to be developed. However, there are also books that contain false accounts of that same person’s death, a false Quantum Mechanical Theory, and other erroneous theories. Moreover, most books are simply unreadable. Despite the Library of Babel containing a wealth of important information, it is practically impossible to take advantage of it. Even if we were somehow able to find the relevant books, we would not be able to judge their validity. The Library of Babel is a low-trust source and exists in a state of maximum entropy.
Today's LLMs are fortunately not generating text based on the uniform distribution. Nevertheless, they are still sampling from an estimated distribution, and they also “hallucinate,” limiting their trustworthiness. Several methods have been employed to ensure that “hallucinations” are limited. In fact, the recent models from major AI companies have improved dramatically in this regard. Some of the methods used include various types of the so-called Guardrails, Reinforcement Learning and, of course, a method called RAG (Retrieval Augmented Generation). What is great about RAG systems is that they allow an LLM to access a database and retrieve relevant information before generating an answer. As a result, the LLM does not rely solely on its so-called parametric memory for facts and can obtain the latest information from a database that may be updated, say, every second. The performance of RAG can be impressive, regardless of the database, which can range from a complex graph database to a simple Excel spreadsheet. Nevertheless, tuning a RAG system to be reliable and useful in practice ends up being quite a complex task - so much so that there are startups that focus on doing just that.
LLMs (and other forms of AI) can also be thought of as a different type of compute node, where the user modifies the prompt (input) in order to get the desired response. A recent development in AI is that of Agents (i.e., meta-AI algorithms that rely on LLMs to perform complex tasks reliably, such as booking a flight ticket online). Agents use LLMs as another form of compute that is quite different from traditional algorithms. While traditional algorithms are exact and deterministic, an LLM adds semantic information and can perform soft matches. The two together can be a powerful combination. In some ways, Agents are attempting to add human traits to traditional computer programs.
The Future of AI
This brings us to the future of AI and the attempt to make computer programs think more similarly to the way humans do. AI is currently excelling in almost every benchmark, often exceeding human performance. Given this, it is natural to ask whether AI models are as capable as humans or whether our benchmarks need to be updated. Recently, a new benchmark called "Humanity’s Last Exam" was created [6]. Interestingly, AI models score quite poorly on it:
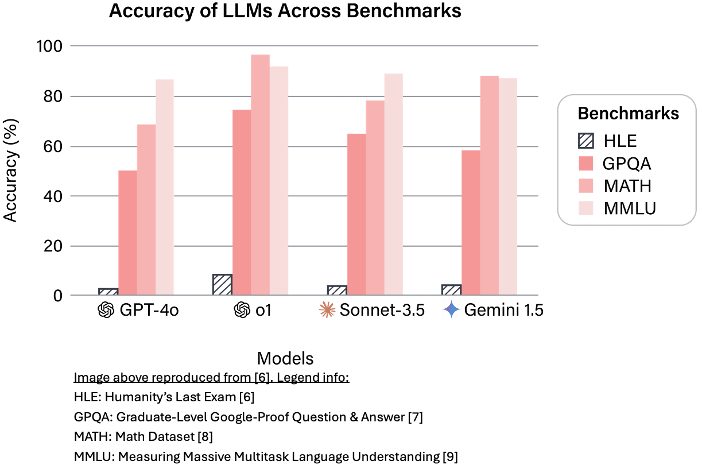
A discussion of the future of AI cannot be complete without including Artificial General Intelligence (AGI) and Superintelligence. While both are relatively nebulous terms, we can think of AGI as aiming to create machines that “think” more like humans do (i.e., generalize better as opposed to being good at a well-defined task), and of Superintelligence as aiming to create machines that are more "intelligent" than humans. Recently, OpenAI’s Sam Altman declared that they know how to build AGI [7]. It should be noted however, that OpenAI has its own definition of AGI as "highly autonomous systems that outperform humans at most economically valuable work" [8]. Other companies, such as Safe Superintelligence, focus on developing superintelligent machines.
Achieving human-level intelligence and, subsequently, Superintelligence is considered the holy grail in the field of AI. There is a great deal of heated debate in both scientific and non-scientific circles about whether this will ever be possible. Despite the interesting arguments of both sides, what makes these conversations especially challenging is the fact that there is no universally accepted definition of intelligence.
It is true that there is no fundamental law of physics that would prevent us from developing artificial intelligence similar to human intelligence, and this is evident: humans, after all, achieve this without violating any law of physics. Therefore, it should be possible, and I certainly hope it will be achieved one day.
Nevertheless, there is an argument to be made that whether AI is “intelligent” or not may be more of a philosophical discussion and a moot point from a practical perspective. AI can be quite different from human intelligence and still have a significant impact. In fact, one could argue that this could be better for our society, as humans would remain relevant. For example, calculators, computers, and finite element models have revolutionized bridge design; however, it is the combination of computers and bridge engineers that is especially powerful.
To draw a parallel between AI and heavier-than-air flight, our airplanes do not fly in the same way that birds or insects do. However, our planes are actually "better" fliers when it comes to aspects we care about, such as speed, payload, and range. It is likely that AI will ultimately look very different from human intelligence, and, like airplanes, it still has a strong chance of revolutionizing our lives and our economy.
References:
[1]: EduKitchen. (January 21, 2023). Chomsky on ChatGPT, Education, Russia and the unvaccinated. (January 21, 2023). Accessed: March 13, 2025. [Online Video]. Available: https://www.youtube.com/watch?v=IgxzcOugvEI
[2]: A. Nathan, J. Grimberg, and A. Rhodes, Eds., “Gen AI: Too much spend, too little benefit? Issue 129.” in Top Of Mind, Jun. 2024. [Online]. Available: https://www.goldmansachs.com/images/migrated/insights/pages/gs-research/gen-ai--too-much-spend%2C-too-little-benefit-/TOM_AI%202.0_ForRedaction.pdf
[3]: D. Bahdanau, K. Cho, and Y. Bengio, "Neural Machine Translation by Jointly Learning to Align and Translate," arXiv preprint, arXiv:1409.0473, 2016. [Online]. Available: https://arxiv.org/abs/1409.0473
[4]: A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, "Attention Is All You Need," arXiv preprint, arXiv:1706.03762, 2023. [Online]. Available: https://arxiv.org/abs/1706.03762
[5]: Stanford University. (Spring term 2013). EE365 “Stochastic Control.”
[6]: L. Phan et al., "Humanity's Last Exam," arXiv preprint arXiv:2501.14249, 2025. [Online]. Available: https://arxiv.org/abs/2501.14249
[7]: S. Altman. “Reflections.” Blog.SamAltman.com. Accessed: March 13, 2025. [Online]. Available: https://blog.samaltman.com/reflections
[8]: OpenAI. “Our structure.” OpenAI.com, Accessed: March 13, 2025. [Online]. Available: https://openai.com/our-structure/